Code Complete
Table of Contents
- Overview
- Chapter 1: Welcome To Software Construction
- Chapter 2: Metaphors
- Chapter 3. Measure Twice, Cut Once: Upstream Prerequisites
- Chapter 4. Key Construction Decisions
- Chapter 5. Design in Construction
- Chapter 6. Working Classes
- Chapter 7. High-Quality Routines
- Chapter 8. Defensive Programming
- 8.1. Protecting Your Program from Invalid Inputs
- 8.2. Assertions
- 8.3. Error-Handling Techniques
- 8.4. Exceptions
- 8.5. Barricade Your Program to Contain the Damage Caused by Errors
- 8.6. Debugging Aids
- 8.7. Determining How Much Defensive Programming to Leave in Production Code
- 8.8. Being Defensive About Defensive Programming
- Additional Resources
- Key Points
- Chapter 9. The Pseudocode Programming Process
- Chapter 10. General Issues in Using Variables
- Chapter 11. The Power of Variable Names
- Chapter 12. Fundamental Data Types
- Chapter 13. Unusual Data Types
- Chapter 14. Organizing Straight-Line Code
- Chapter 15. Using Conditionals
- Chapter 16. Controlling Loops
- Chapter 17. Unusual Control Structures
- Chapter 18. Table-Driven Methods
- Chapter 19. General Control Issues
- Chapter 23. Debugging
- Chapter 24. Refactoring
- Chapter 25. Code-Tuning Strategies
- Chapter 28. Managing Construction
Overview
Book Website
cc2e.com/1234
Chapter 1: Welcome To Software Construction
1.1 What Is Software Construction?
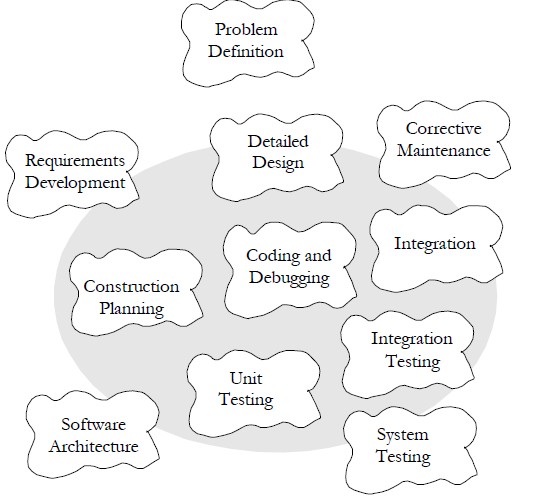
Here are some of the specific tasks involved in construction:
- Verifying that the groundwork has been laid so that construction can proceed successfully
- Determining how your code will be tested
- Designing and writing classes and routines
- Creating and naming variables and named constants
- Selecting control structures and organizing blocks of statements
- Unit testing, integration testing, and debugging your own code
- Reviewing other team members' low-level designs and code and having them review yours
- Polishing code by carefully formatting and commenting it
- Integrating software components that were created separately
- Tuning code to make it faster and use fewer resources
1.2 Why Is Software Construction Important?
- Construction is a large part of software development
- Construction is the central activity in software development
- With a focus on construction, the individual programmer’s productivity can improve enormously
- Construction’s product, the source code, is often the only accurate description of the software
- Construction is the only activity that’s guaranteed to be done
1.3 How to Read This Book
Chapter 2: Metaphors
2.1 The Importance of Metaphors
Important developments often arise out of analogies. By comparing a topic you understand poorly to something similar you understand better, you can come up with insights that result in a better understanding of the less-familiar topic. This use of metaphor is called “modeling.”
2.2 How to Use Software Metaphor
A heuristic is a technique that helps you look for an answer. Its results are subject to chance because a heuristic tells you only how to look, not what to find. It doesn’t tell you how to get directly from point A to point B; it might not even know where point A and point B are. In effect, a heuristic is an algorithm in a clown suit. It’s less predictable, it’s more fun, and it comes without a 30-day money-back guarantee.
2.3 Common Software Metaphors
Additional Resources
cc2e.com/0285
Among general books on metaphors, models, and paradigms, the touchstone book is by Thomas Kuhn.
Kuhn, Thomas S. The Structure of Scientific Revolutions, 3d ed. Chicago, IL: The University of Chicago Press, 1996. Kuhn's book on how scientific theories emerge,evolve, and succumb to other theories in a Darwinian cycle set the philosophy of science on its ear when it was first published in 1962. It's clear and short, and it's loaded with interesting examples of the rise and fall of metaphors, models, and paradigms in science.
Floyd, Robert W. "The Paradigms of Programming." 1978 Turing Award Lecture. Communications of the ACM, August 1979, pp. 455–60. This is a fascinating discussion of models in software development, and Floyd applies Kuhn's ideas to the topic.
Key Points
- Metaphors are heuristics, not algorithms. As such, they tend to be a little sloppy.
- Metaphors help you understand the software-development process by relating it to other activities you already know about.
- Some metaphors are better than others.
- Treating software construction as similar to building construction suggests that careful preparation is needed and illuminates the difference between large and small projects.
- Thinking of software-development practices as tools in an intellectual toolbox suggests further that every programmer has many tools and that no single tool is right for every job. Choosing the right tool for each problem is one key to being an effective programmer.
- Metaphors are not mutually exclusive. Use the combination of metaphors that works best for you.
Chapter 3. Measure Twice, Cut Once: Upstream Prerequisites
3.1. Importance of Prerequisites
3.2. Determine the Kind of Software You're Working On
Choosing Between Iterative and Sequential Approaches
You might choose a more sequential (up-front) approach when
- The requirements are fairly stable.
- The design is straightforward and fairly well understood.
- The development team is familiar with the applications area.
- The project contains little risk.
- Long-term predictability is important.
- The cost of changing requirements, design, and code downstream is likely to be high.
You might choose a more iterative (as-you-go) approach when
- The requirements are not well understood or you expect them to be unstable for other reasons.
- The design is complex, challenging, or both.
- The development team is unfamiliar with the applications area.
- The project contains a lot of risk.
- Long-term predictability is not important.
- The cost of changing requirements, design, and code downstream is likely to be low.
3.3. Problem-Definition Prerequisite
The penalty for failing to define the problem is that you can waste a lot of time solving the wrong problem. This is a double-barreled penalty because you also don't solve the right problem.
3.4. Requirements Prerequisite
Explicit requirements help to ensure that the user rather than the programmer drives the system's functionality. If the requirements are explicit, the user can review them and agree to them. If they're not, the programmer usually ends up making requirements decisions during programming. Explicit requirements keep you from guessing what the user wants.
Handling Requirements Changes During Construction
- Use the requirements checklist at the end of the section to assess the quality of your requirements If your requirements aren't good enough, stop work, back up, and make them right before you proceed. Sure, it feels like you're getting behind if you stop coding at this stage.
- Make sure everyone knows the cost of requirements changes
- Set up a change-control procedure
- Use development approaches that accommodate changes
- Dump the project If the requirements are especially bad or volatile and none of the suggestions above are workable, cancel the project.
- Keep your eye on the business case for the project Many requirements issues disappear before your eyes when you refer back to the business reason for doing the project.
3.5. Architecture Prerequisite
Why have architecture as a prerequisite? Because the quality of the architecture determines the conceptual integrity of the system. That in turn determines the ultimate quality of the system. A wellthought- out architecture provides the structure needed to maintain a system's conceptual integrity from the top levels down to the bottom. It provides guidance to programmers—at a level of detail appropriate to the skills of the programmers and to the job at hand. It partitions the work so that multiple developers or multiple development teams can work independently.
3.6. Amount of Time to Spend on Upstream Prerequisites
The amount of time to spend on problem definition, requirements, and software architecture varies according to the needs of your project. Generally, a well-run project devotes about 10 to 20 percent of its effort and about 20 to 30 percent of its schedule to requirements, architecture, and up-front planning (McConnell 1998, Kruchten 2000).
Additional Resources
cc2e.com/0344
Chapter 4. Key Construction Decisions
4.1. Choice of Programming Language
4.2. Programming Conventions
Before construction begins, spell out the programming conventions you'll use. Coding-convention details are at such a level of precision that they're nearly impossible to retrofit into software after it's written. Details of such conventions are provided throughout the book.
4.3. Your Location on the Technology Wave
Understanding the distinction between programming in a language and programming into one is critical to understanding this book. Most of the important programming principles depend not on specific languages but on the way you use them. If your language lacks constructs that you want to use or is prone to other kinds of problems, try to compensate for them. Invent your own coding conventions, standards, class libraries, and other augmentations.
4.4. Selection of Major Construction Practices
Key Points
- Every programming language has strengths and weaknesses. Be aware of the specific strengths and weaknesses of the language you're using.
- Establish programming conventions before you begin programming. It's nearly impossible to change code to match them later.
- More construction practices exist than you can use on any single project. Consciously choose the practices that are best suited to your project.
- Ask yourself whether the programming practices you're using are a response to the programming language you're using or controlled by it. Remember to program into the language, rather than programming in it.
- Your position on the technology wave determines what approaches will be effective—or even possible. Identify where you are on the technology wave, and adjust your plans and expectations accordingly.
Chapter 5. Design in Construction
5.1. Design Challenges
The phrase "software design" means the conception, invention, or contrivance of a scheme for turning a specification for computer software into operational software. Design is the activity that links requirements to coding and debugging. A good top-level design provides a structure that can safely contain multiple lower-level designs. Good design is useful on small projects and indispensable on large projects.
5.2. Key Design Concepts
- Software's Primary Technical Imperative: Managing Complexity
Managing complexity is the most important technical topic in software development. In my view, it's so important that Software's Primary Technical Imperative has to be managing complexity.
At the software-architecture level, the complexity of a problem is reduced by dividing the system into subsystems. Humans have an easier time comprehending several simple pieces of information than one complicated piece. The goal of all software-design techniques is to break a complicated problem into simple pieces. The more independent the subsystems are, the more you make it safe to focus on one bit of complexity at a time. Carefully defined objects separate concerns so that you can focus on one thing at a time. Packages provide the same benefit at a higher level of aggregation.
- How to Attack Complexity
- Minimize the amount of essential complexity that anyone's brain has to deal with at any one time.
- Keep accidental complexity from needlessly proliferating.
- Desirable Characteristics of a Design
- Minimal complexity The primary goal of design should be to minimize complexity for all the reasons just described.
- Ease of maintenance Ease of maintenance means designing for the maintenance programmer.
- Loose coupling Loose coupling means designing so that you hold connections among different parts of a program to a minimum.
- Extensibility Extensibility means that you can enhance a system without causing violence to the underlying structure.
- Reusability Reusability means designing the system so that you can reuse pieces of it in other systems.
- High fan-in High fan-in refers to having a high number of classes that use a given class.
- Low-to-medium fan-out Low-to-medium fan-out means having a given class use a low-to-medium number of other classes. High fan-out (more than about seven) indicates that a class uses a large number of other classes and may therefore be overly complex.
- Portability Portability means designing the system so that you can easily move it to another environment.
- Leanness Leanness means designing the system so that it has no extra parts
- Stratification Stratification means trying to keep the levels of decomposition stratified so that you can view the system at any single level and get a consistent view. Design the system so that you can view it at one level without dipping into other levels.
- Standard techniques The more a system relies on exotic pieces, the more intimidating it will be for someone trying to understand it the first time. Try to give the whole system a familiar feeling by using standardized, common approaches.
- Levels of Design
- Level 1: Software System
- Level 2: Division into Subsystems or Packages
Of particular importance at this level are the rules about how the various subsystems can communicate. If all subsystems can communicate with all other subsystems, you lose the benefit of separating them at all. Make each subsystem meaningful by restricting communications.
- Level 3: Division into Classes
Classes vs. Objects A key concept in object-oriented design is the differentiation between objects and classes. An object is any specific entity that exists in your program at run time. A class is the static thing you look at in the program listing. An object is the dynamic thing with specific values and attributes you see when you run the program. For example, you could declare a class Person that had attributes of name, age, gender, and so on. At run time you would have the objects nancy, hank, diane, tony, and so on—that is, specific instances of the class.
- Level 4: Division into Routines
- Level 5: Internal Routine Design
- Level 1: Software System
5.3. Design Building Blocks: Heuristics
- Value of Information Hiding
Information hiding is one of the few theoretical techniques that has indisputably proven its value in practice, which has been true for a long time (Boehm 1987a). Large programs that use information hiding were found years ago to be easier to modify—by a factor of 4—than programs that don't (Korson and Vaishnavi 1986). Moreover, information hiding is part of the foundation of both structured design and object-oriented design.
5.4. Design Practices
Key Points
- Software's Primary Technical Imperative is managing complexity. This is greatly aided by a design focus on simplicity.
- Simplicity is achieved in two general ways: minimizing the amount of essential complexity that anyone's brain has to deal with at any one time, and keeping accidental complexity from proliferating needlessly.
- Design is heuristic. Dogmatic adherence to any single methodology hurts creativity and hurts your programs.
- Good design is iterative; the more design possibilities you try, the better your final design will be.
- Information hiding is a particularly valuable concept. Asking "What should I hide?" settles many difficult design issues.
- Lots of useful, interesting information on design is available outside this book. The perspectives presented here are just the tip of the iceberg.
Chapter 6. Working Classes
6.1. Class Foundations: Abstract Data Types (ADTs)
- ADTs and Classes
Abstract data types form the foundation for the concept of classes. In languages that support classes, you can implement each abstract data type as its own class. Classes usually involve the additional concepts of inheritance and polymorphism. One way of thinking of a class is as an abstract data type plus inheritance and polymorphism.
6.2. Good Class Interfaces
6.3. Design and Implementation Issues
This section discusses issues related to containment, inheritance, member functions and data, class coupling, constructors, and value-vs.-reference objects.
- Containment ("has a" Relationships)
Containment is the simple idea that a class contains a primitive data element or object. A lot more is written about inheritance than about containment, but that's because inheritance is more tricky and error-prone, not because it's better. Containment is the work-horse technique in object-oriented programming.
- Inheritance ("is a" Relationships)
Inheritance is the idea that one class is a specialization of another class. The purpose of inheritance is to create simpler code by defining a base class that specifies common elements of two or more derived classes.
When you decide to use inheritance, you have to make several decisions:
- For each member routine, will the routine be visible to derived classes? Will it have a default implementation? Will the default implementation be overridable?
- For each data member (including variables, named constants, enumerations, and so on), will the data member be visible to derived classes?
- Why Are There So Many Rules for Inheritance?
This section has presented numerous rules for staying out of trouble with inheritance. The underlying message of all these rules is that inheritance tends to work against the primary technical imperative you have as a programmer, which is to manage complexity. For the sake of controlling complexity, you should maintain a heavy bias against inheritance. Here's a summary of when to use inheritance and when to use containment:
- If multiple classes share common data but not behavior, create a common object that those classes can contain.
- If multiple classes share common behavior but not data, derive them from a common base class that defines the common routines.
- If multiple classes share common data and behavior, inherit from a common base class that defines the common data and routines.
- Inherit when you want the base class to control your interface; contain when you want to control your interface.
6.4. Reasons to Create a Class
- Summary of Reasons to Create a Class
Here's a summary list of the valid reasons to create a class: • Model real-world objects • Model abstract objects • Reduce complexity • Isolate complexity • Hide implementation details • Limit effects of changes • Hide global data • Streamline parameter passing • Make central points of control • Facilitate reusable code • Plan for a family of programs • Package related operations • Accomplish a specific refactoring
6.5. Language-Specific Issues
6.6. Beyond Classes: Packages
Key Points
- Class interfaces should provide a consistent abstraction. Many problems arise from violating this single principle.
- A class interface should hide something—a system interface, a design decision, or an implementation detail.
- Containment is usually preferable to inheritance unless you're modeling an "is a" relationship.
- Inheritance is a useful tool, but it adds complexity, which is counter to Software's Primary Technical Imperative of managing complexity.
- Classes are your primary tool for managing complexity. Give their design as much attention as needed to accomplish that objective.
Chapter 7. High-Quality Routines
Here's a hint: you should be able to find at least 10 different problems with it. Once you've come up with your own list, look at the following list:
- The routine has a bad name. HandleStuff() tells you nothing about what the routine does.
- The routine isn't documented. (The subject of documentation extends beyond the boundaries of individual routines and is discussed in Chapter 32, "Self- Documenting Code.")
- The routine has a bad layout. The physical organization of the code
on the page gives few hints about its logical organization. Layout
strategies are used haphazardly, with different styles in different
parts of the routine. Compare the styles where expenseType
= 2 and expenseType =3. (Layout is discussed in Chapter 31, "Layout and Style.") - The routine's input variable, inputRec, is changed. If it's an input variable, its value should not be modified (and in C++ it should be declared const). If the value of the variable is supposed to be modified, the variable should not be called inputRec.
- The routine reads and writes global variables—it reads from corpExpense and writes to profit. It should communicate with other routines more directly than by reading and writing global variables.
- The routine doesn't have a single purpose. It initializes some variables, writes to a database, does some calculations—none of which seem to be related to each other in any way. A routine should have a single, clearly defined purpose.
- The routine doesn't defend itself against bad data. If crntQtr equals 0, the expression ytdRevenue * 4.0 / (double) crntQtr causes a divide-by-zero error.
- The routine uses several magic numbers: 100, 4.0, 12, 2, and 3. Magic numbers are discussed in Section 12.1, "Numbers in General."
- Some of the routine's parameters are unused: screenX and screenY are not referenced within the routine.
- One of the routine's parameters is passed incorrectly: prevColor is labeled as a reference parameter (&) even though it isn't assigned a value within the routine.
- The routine has too many parameters. The upper limit for an understandable number of parameters is about 7; this routine has 11. The parameters are laid out in such an unreadable way that most people wouldn't try to examine them closely or even count them.
- The routine's parameters are poorly ordered and are not documented. (Parameter ordering is discussed in this chapter. Documentation is discussed in Chapter 32.)
7.1. Valid Reasons to Create a Routine
- Summary of Reasons to Create a Routine
Here's a summary list of the valid reasons for creating a routine:
- Reduce complexity
- Introduce an intermediate, understandable abstraction
- Avoid duplicate code
- Support subclassing
- Hide sequences
- Hide pointer operations
- Improve portability
- Simplify complicated boolean tests
- Improve performance
In addition, many of the reasons to create a class are also good reasons to create a routine:
- Isolate complexity
- Hide implementation details
- Limit effects of changes
- Hide global data
- Make central points of control
- Facilitate reusable code
- Accomplish a specific refactoring
7.2. Design at the Routine Level
7.3. Good Routine Names
7.4. How Long Can a Routine Be?
7.5. How to Use Routine Parameters
What kinds of interface assumptions about parameters should you document? • Whether parameters are input-only, modified, or output-only • Units of numeric parameters (inches, feet, meters, and so on) • Meanings of status codes and error values if enumerated types aren't used • Ranges of expected values • Specific values that should never appear
7.6. Special Considerations in the Use of Functions
7.7. Macro Routines and Inline Routines
- Limitations on the Use of Macro Routines
Modern languages like C++ provide numerous alternatives to the use of macros: • const for declaring constant values • inline for defining functions that will be compiled as inline code • template for defining standard operations like min, max, and so on in a type-safe way • enum for defining enumerated types • typedef for defining simple type substitutions
Key Points
- The most important reason for creating a routine is to improve the intellectual manageability of a program, and you can create a routine for many other good reasons. Saving space is a minor reason; improved readability, reliability, and modifiability are better reasons.
- Sometimes the operation that most benefits from being put into a routine of its own is a simple one.
- You can classify routines into various kinds of cohesion, but you can make most routines functionally cohesive, which is best.
- The name of a routine is an indication of its quality. If the name is bad and it's accurate, the routine might be poorly designed. If the name is bad and it's inaccurate, it's not telling you what the program does. Either way, a bad name means that the program needs to be changed.
- Functions should be used only when the primary purpose of the function is to return the specific value described by the function's name.
- Careful programmers use macro routines with care and only as a last resort.
Chapter 8. Defensive Programming
8.1. Protecting Your Program from Invalid Inputs
8.2. Assertions
8.3. Error-Handling Techniques
8.4. Exceptions
Exceptions are a specific means by which code can pass along errors or exceptional events to the code that called it. If code in one routine encounters an unexpected condition that it doesn't know how to handle, it throws an exception, essentially throwing up its hands and yelling, "I don't know what to do about this—I sure hope somebody else knows how to handle it!"
8.5. Barricade Your Program to Contain the Damage Caused by Errors
8.6. Debugging Aids
8.7. Determining How Much Defensive Programming to Leave in Production Code
8.8. Being Defensive About Defensive Programming
Additional Resources
Key Points
- Production code should handle errors in a more sophisticated way than "garbage in, garbage out."
- Defensive-programming techniques make errors easier to find, easier to fix, and less damaging to production code.
- Assertions can help detect errors early, especially in large systems, highreliability systems, and fast-changing code bases.
- The decision about how to handle bad inputs is a key error-handling decision and a key high-level design decision.
- Exceptions provide a means of handling errors that operates in a different dimension from the normal flow of the code. They are a valuable addition to the programmer's intellectual toolbox when used with care, and they should be weighed against other error-processing techniques.
- Constraints that apply to the production system do not necessarily apply to the development version. You can use that to your advantage, adding code to the development version that helps to flush out errors quickly.
Chapter 9. The Pseudocode Programming Process
9.1. Summary of Steps in Building Classes and Routines
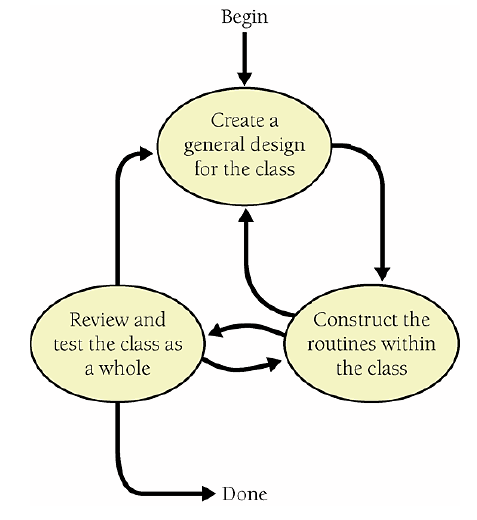
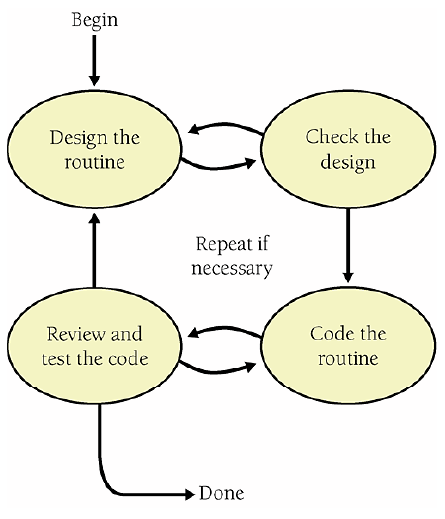
9.2. Pseudocode for Pros
9.3. Constructing Routines by Using the PPP
9.4. Alternatives to the PPP
- Test-first development
Test-first is a popular development style in which test cases are written prior to writing any code.
- Refactoring
Refactoring is a development approach in which you improve code through a series of semantic preserving transformations.
- Design by contract
Design by contract is a development approach in which each routine is considered to have preconditions and postconditions.
Key Points
- Constructing classes and constructing routines tends to be an iterative process. Insights gained while constructing specific routines tend to ripple back through the class's design.
- Writing good pseudocode calls for using understandable English, avoiding features specific to a single programming language, and writing at the level of intent (describing what the design does rather than how it will do it).
- The Pseudocode Programming Process is a useful tool for detailed design and makes coding easy. Pseudocode translates directly into comments, ensuring that the comments are accurate and useful.
- Don't settle for the first design you think of. Iterate through multiple approaches in pseudocode and pick the best approach before you begin writing code.
- Check your work at each step, and encourage others to check it too. That way, you'll catch mistakes at the least expensive level, when you've invested the least amount of effort.
Chapter 10. General Issues in Using Variables
10.1. Data Literacy
10.2. Making Variable Declarations Easy
10.3. Guidelines for Initializing Variables
10.4. Scope
10.5. Persistence
10.6. Binding Time
To summarize, following are the times a variable can be bound to a value in this example. (The details could vary somewhat in other cases.)
- Coding time (use of magic numbers)
- Compile time (use of a named constant)
- Load time (reading a value from an external source such as the Windows registry file or a Java properties file)
- Object instantiation time (such as reading the value each time a window is created)
- Just in time (such as reading the value each time the window is drawn)
10.7. Relationship Between Data Types and Control Structures
10.8. Using Each Variable for Exactly One Purpose
Chapter 11. The Power of Variable Names
11.1. Considerations in Choosing Good Names
- The Most Important Naming Consideration
The most important consideration in naming a variable is that the name fully and accurately describe the entity the variable represents. An effective technique for coming up with a good name is to state in words what the variable represents. Often that statement itself is the best variable name. It's easy to read because it doesn't contain cryptic abbreviations, and it's unambiguous. Because it's a full description of the entity, it won't be confused with something else. And it's easy to remember because the name is similar to the concept.
11.2. Naming Specific Types of Data
11.3. The Power of Naming Conventions
11.4. Informal Naming Conventions
11.5. Standardized Prefixes
11.6. Creating Short Names That Are Readable
11.7. Kinds of Names to Avoid
Chapter 12. Fundamental Data Types
12.1. Numbers in General
12.2. Integers
12.3. Floating-Point Numbers
12.4. Characters and Strings
12.5. Boolean Variables
12.6. Enumerated Types
12.7. Named Constants
12.8. Arrays
12.9. Creating Your Own Types (Type Aliasing)
Chapter 13. Unusual Data Types
13.1. Structures
13.2. Pointers
13.3. Global Data
Chapter 14. Organizing Straight-Line Code
14.1. Statements That Must Be in a Specific Order
14.2. Statements Whose Order Doesn't Matter
The guiding principle is the Principle of Proximity: Keep related actions together.
Chapter 15. Using Conditionals
15.1. if Statements
15.2. case Statements
Chapter 16. Controlling Loops
16.1. Selecting the Kind of Loop
16.2. Controlling the Loop
16.3. Creating Loops Easily—From the Inside Out
16.4. Correspondence Between Loops and Arrays
Chapter 17. Unusual Control Structures
17.1. Multiple Returns from a Routine
17.2. Recursion
17.3. goto
- Summary of Guidelines for Using gotos
Use of gotos is a matter of religion. My dogma is that in modern languages, you can easily replace nine out of ten gotos with equivalent sequential constructs. In these simple cases, you should replace gotos out of habit. In the hard cases, you can still exorcise the goto in nine out of ten cases: You can break the code into smaller routines, use try-finally, use nested ifs, test and retest a status variable, or restructure a conditional. Eliminating the goto is harder in these cases, but it's good mental exercise and the techniques discussed in this section give you the tools to do it.
17.4. Perspective on Unusual Control Structures
Chapter 18. Table-Driven Methods
18.1. General Considerations in Using Table-Driven Methods
18.2. Direct Access Tables
18.3. Indexed Access Tables
18.4. Stair-Step Access Tables
18.5. Other Examples of Table Lookups
Chapter 19. General Control Issues
19.1. Boolean Expressions
19.2. Compound Statements (Blocks)
19.3. Null Statements
19.4. Taming Dangerously Deep Nesting
19.5. A Programming Foundation: Structured Programming
19.6. Control Structures and Complexity
Chapter 23. Debugging
23.1. Overview of Debugging Issues
23.2. Finding a Defect
23.3. Fixing a Defect
23.4. Psychological Considerations in Debugging
23.5. Debugging Tools—Obvious and Not-So-Obvious
Chapter 24. Refactoring
24.1. Kinds of Software Evolution
24.2. Introduction to Refactoring
24.3. Specific Refactorings
24.4. Refactoring Safely
24.5. Refactoring Strategies
Chapter 25. Code-Tuning Strategies
You can address performance concerns at two levels: strategic and tactical.