System calls
Table of Contents
用户程序看来,kernel是一个透明的系统层,它一直在那却不被注意.进程不知道 kernel是否运行.然而,进程一直与kernel交互着请求系统资源,访问外围设备,与其他进程通信,读文件等等.为达到这写目的,它们使用标准库函数来调用内核函数.
系统调用(system calls)被用来调用内核函数从用户应用.这里主要分析一下 system call如何与标准库相关,运行机制,如何实现等.
Basics of System Programming
随着编程语言趋于更高层的抽象化,系统编程的真正意义慢慢被腐蚀.为什么要麻烦去理解系统细节呢.拥有千兆字节或兆兆字节数据的数据库需要知道底层操作系统使用什么机制读取它们的文件和原始数据,以至修改数据库代码达到最大化的执行.
Tracing System Calls
如下例子来看system calls如何被封装在标准库中然后被调用:
#include<stdio.h> #include<fcntl.h> #include<unistd.h> #include<malloc.h> int main() { int handle, bytes; void* ptr; handle = open("/tmp/test.txt", O_RDONLY); ptr = (void*)malloc(150); bytes = read(handle, ptr, 150); printf("%s", ptr); close(handle); return 0; }
多少个系统调用被这个程序所使用呢?初看有 open, read, close.
使用工具 strace 可以记录应用使用的所有系统调用.如下对上面的 test
做记录:
$ strace -o log.txt ./test
log.txt 的内容如下:
execve("./test", ["./test"], [/* 47 vars */]) = 0 brk(0) = 0x9111000 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7729000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 fstat64(3, {st_mode=S_IFREG|0644, st_size=100251, ...}) = 0 mmap2(NULL, 100251, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7710000 close(3) = 0 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) open("/lib/i386-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 read(3, "\177ELF\1\1\1\0\0\0\0\0\0\0\0\0\3\0\3\0\1\0\0\0000\226\1\0004\0\0\0"..., 512) = 512 fstat64(3, {st_mode=S_IFREG|0755, st_size=1734120, ...}) = 0 mmap2(NULL, 1743580, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7566000 mmap2(0xb770a000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1a4) = 0xb770a000 mmap2(0xb770d000, 10972, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb770d000 close(3) = 0 mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7565000 set_thread_area({entry_number:-1 -> 6, base_addr:0xb7565900, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0 mprotect(0xb770a000, 8192, PROT_READ) = 0 mprotect(0x8049000, 4096, PROT_READ) = 0 mprotect(0xb774c000, 4096, PROT_READ) = 0 munmap(0xb7710000, 100251) = 0 open("/tmp/test.txt", O_RDONLY) = -1 ENOENT (No such file or directory) brk(0) = 0x9111000 brk(0x9132000) = 0x9132000 read(-1, 0x9111008, 150) = -1 EBADF (Bad file descriptor) close(-1) = -1 EBADF (Bad file descriptor) exit_group(0) = ?
trace log显示这个应用程序使用了一大堆不是明显在源代码中的系统调用.所以两者有着强烈的依赖关系.
Supported Standards
在Unix类的系统中,system calls是比较重要地位的.她们的范围和速度,实现的效率在系统执行中占有很多的重要角色.Unix的分支众多,不同的标准提出来规范它们系统调用的接口.
POSIX标准(Portable Operating System Interface forUnix)成为主要的标准.Linux和C标准库都极力与它兼容.
除了POSIX,在UNIX历史中,2大主要发展线路: System V(来自于初始AT&T代码) 和BSD(Berkeley Software Distribution由University of California开发,现在以NetBSD, FreeBSD, OpenBSD, BSDI 和 MacOS X为代表).
Linux形成它自己独立的system calls从如上所有三者.比如,如下3个有名的 system calls源自于这3大阵营:
flock锁文件防止多个进程并行访问.来自POSIX标准.- BSD UNIX提供
truncate调用来节短一个文件.Linux也以同样名字实现这个函数. sysfs收集文件系统的信息由System V Release 4引入.Linux也采用这个 system call.
一些system calls被三个标准同时要求.比如 time, gettimeofday 等.
同样,一些system calls只在Linux特定开发,不存在其他标准中.
Restarting System Calls
当system calls与signals发生冲突时,有趣的问题就产生了.当一个system call 正在被执行,同时一个紧急的signal被发送到这个进程,那么两者的优先执行怎么处理?是signal等待直到system call终结,还是调用被中断以致signal能尽快被传递?第一种选择明显触发极少问题,并且是更简单的方法.不幸的是,它仅仅适用当所有system calls快速的终结并且不让进程等待太长时间.但这并不总是如此.System calls不仅需要一定的时间来执行,而且在最差的情况下,它们也会进入睡眠.这样的情况必须被防止.
如果执行中的system call被中断,kernel返回什么值给应用呢?在正常情况,只有
2中情况:调用不是成功就是失败.在中断情况中,第三种情况产生:应用被告知
system call在执行中被signal中断.在此情况下, -EINTR 被使用.
此种过程的缺点也是明显的.尽管它容易被实现,但它强制要求用户应用编程者明显的检查所有被中断system call的返回值是否是 -EINTR. 如果是这个值的话,就重新不断重启这个call直到不被signal中断.System calls以这种情况重启被称为 restartable system calls.
这种行为由System V Unix引入和采用,也是Linux默认的方式.但BSD不采用此方法,当此情况发生,call不返回值而是kernel自动重启这个call当signal处理终结.Linux通过 SA_RESTART 标示来支持BSD这种方式.
看如下例子看两者的区别:
#include <signal.h> #include <stdio.h> #include <unistd.h> volatile int signaled = 0; void handler (int signum) { printf("signaled called\n"); signaled = 1; } int main() { char ch; struct sigaction sigact; sigact.sa_handler = handler; sigact.sa_flags = SA_RESTART; sigaction(SIGINT, &sigact, NULL); while (read(STDIN_FILENO, &ch, 1) != 1 && !signaled); }
有个while循环,满足如下条件之一程序完成:
- read到一个字节.
- 变量signaled被设置为1.
先注释掉 sigact.sa_flags = SA_RESTART; ,看System V下如何,运行程序,CTRL-C去中断它,signaled被设置,程序退出.
BSD下,运行程序,CTRL-C去中断它,signal处理得到调用并打印,BSD机制重启read 操作,并且!signaled没有被有效,程序不能在被SIGNIT signal终结.
Available System Calls
每个system call有符号定植表示,它们的平台依赖定义在
<asm-arch/unistd.h>,大约到达200个.最后把system calls按照功能分类使得编程者更容易使用.如下提取主要的system calls分类:
Process Management
- fork and vfork split an existing process into two new processes as. clone is an enhanced version offorkthat supports, among other things, the generation of threads.
- exit ends a process and frees its resources.
- A whole host of system calls exist to query (and set) process properties such as PID, UID, and so on.; most of these calls simply read or modify a field in the task structure. The following can be read: PID, GID, PPID, SID, UID, EUID, PGID, EGID, and PGRP. The following can be set: UID, GID, REUID, REGID, SID, SUID, and FSGID. System calls are named in accordance with a logical scheme that uses designations such as setgid,setuid,and geteuid.
- personality defines the execution environment of an application and is used, for instance, in the implementation of binary emulations.
- ptrace enables system call tracing and is the platform on which the above strace tool builds.
- nice sets the priority of normal processes by assigning a number between −20 and 19 in descending order of importance. Only root processes (or processes with theCAPSYSNICE permission) are allowed to specify negative values.
- setrlimitis used to set certain resource limits, for example, CPU time or the maximum permitted number of child processes.getrlimitqueries the current limits (i.e., maximum permitted values), and getrusage queries current resource usage to check whether the process is still within the defined resource limits.
Time Operations
- adjtimex reads and sets time-based kernel variables to control kernel time behavior.
- alarm and setitimer set up alarms and interval timers to defer actions to a later time. getitimer reads settings.
- gettimeofday and settimeofday get and set the current system time, respectively. Unlike times, they also take account of the current time zone and daylight saving time.
- sleep and nanosleep suspend process execution for a defined interval;nanosleepdefines high-precision intervals.
- time returns the number of seconds since midnight on January 1, 1970 (this date is the classic time base for Unix systems).stimesets this value and therefore changes the current system date.
Signal Handling
- signal installs signal handler functions.sigaction is a modern, enhanced version that supports additional options and provides greater flexibility.
- sigpending checks whether signals are pending for the process but are currently blocked.
- sigsuspend places the process on the wait queue until a specific signal (from a set of signals) arrives.
- setmask enables signal blocking, whilegetmaskreturns a list of all currently blocked signals.
- killis used to send any signals to a process.
- The same system calls are available to handle real-time signals.
However, their function names are prefixed with
rt_. For example,rt_sigactioninstalls a real-time signal handler, andrt_sigsuspendputs the process in a wait state until a specific signal (from a set of signals) arrives.
Scheduling
- setpriority and getpriority set and get the priority of a process and are therefore key system calls for scheduling purposes.
sched_setschedulerandsched_getschedulerset and query scheduling classes.sched_setparamandsched_getparamset and query additional scheduling parameters of processes (currently, only the parameter for real-time priority is used).sched_yieldvoluntarily relinquishes control even when CPU time is still available to the process.
Modules
init_moduleadds a new module.delete_moduleremoves a module from the kernel.
Filesystem
- Some system calls are used as a direct basis for userspace utilities of the same name that create and modify the directory structure:chdir, mkdir,rmdir,rename,symlink,getcwd, chroot,umask,andmknod.
- File and directory attributes can be modified using chown and chmod.
- The following utilities for processing file contents are implemented in the standard library and have the same names as the system calls:open, close, readandreadv, writeand writev,truncate and llseek.
- readdir and getdents read directory structures.
- link,symlink,and unlink create and delete links (or files if they are the last element in a hard link);readlink reads the contents of a link.
- mount and umount are used to attach and detach filesystems.
- poll and select are used to wait for some event.
- execve loads a new process in place of an old process. It starts new programs when used in conjunction with fork.
Memory Management
- In terms of dynamic memory management, the most important call
is
brk, which modifies the size of the process data segment. Programs that invokemallocor similar functions (almost all nontrivial code) make frequent use of this system call. - mmap, mmap2, munmap,and mremap perform mapping, unmapping, and remapping operations, while mprotect and madvise control access to and give advice about specific regions of virtual memory.
- swapon and swapoff enable and disable (additional) swap space on external storage devices.
Interprocess Communication and Network Functions
- socketcall deals with network questions and is used to implement socket abstraction.
- ipc is the counterpart to socketcall and is used for process connections local to the computer and not for connections established via networks.
System Information and Settings
- syslog writes messages to the system logs and permits the assignment of different priorities.
- sysinfo returns information on the state of the system, particularly statistics on memory usage.
- sysctlis used to ‘‘fine-tune‘‘ kernel parameters.
System Security and Capabilities
- capset and capgetare responsible for setting and querying process capabilities.
- securityis a system call multiplexer for implementing LSM.
Implementation of System Calls
Structure of System Calls
实现system calls的代码分为2部分.system call调用的任务是以C实现的,与其他kernel代码一样.但其中是对平台特定的特性和对许多细节处理的封装,最终以汇编代码实现.
- Implementation of Handler Functions
这些函数分布在kernel中,因为它们是嵌入code sections中的,所以它们以它们目的文件紧密相连.比如,文件相关的system calls在
fs/kernel子目录中,因为它们与虚拟系统交互.同样所有内存管理调用在mm/子目录中.用来实现system calls的处理函数共享一些格式:
- 每个函数以
sys_为前缀表明函数是system call. - 所有处理函数最多接受5个参数.
- 所有system calls执行在kernel模式下.
在kernel与user模式之间转换有平台特定的代码实现,而处理函数
handler基本以平台不相关代码实现,这样就把处理函数与平台特定的代码独立开来,实现它与其他内核代码类似.system call的基本调用流程如下: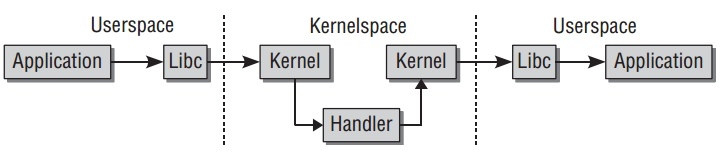
一些system calls比较简单,一些比较复杂,一些作为多路器.如下简单的和作为多路器的例子:
// kernel/timer.c asmlinkage long sys_getuid(void) { /* Only we change this so SMP safe */ return current->uid; } // net/socket.c asmlinkage long sys_socketcall(int call, unsigned long __user *args) { unsigned long a[6]; unsigned long a0,a1; int err; // ... switch(call) { case SYS_SOCKET: err = sys_socket(a0,a1,a[2]); break; case SYS_BIND: err = sys_bind(a0,(struct sockaddr __user *)a1, a[2]); break; case SYS_CONNECT: err = sys_connect(a0, (struct sockaddr __user *)a1, a[2]); break; // ... default: err = -EINVAL; break; } return err; }
每个函数声明都有一个
asmlinkage标识,不是标准C的语法.asmlinkage是一个汇编宏,定义在<linkage.h>. - 每个函数以
- Dispatching and Parameter Passing
System calls唯一的以一个数字来标识.所有的calls由一个中心代码处理,使用这个数字去调用特定函数通过查询一个静态表.参数传递也由这个中心代码处理, 所以代码传递的实现与system call是独立的.
从user转到kernel模式,参数的传递以汇编代码实现来适应特定的平台特性. 参数传递直接在寄存器中在所有平台上.更多一个寄存器需要来存储system call的数字被使用来之后查找到相应的处理函数.
IA-32为例, 指令
int $0x80转到kernel模式, system call数字在寄存器eax,其他参数在 ebx, ecx, edx,esi,和edi.sys_call_table的表格维护一组指向处理函数的函数指针,并在所有平台上.因为这个表格由汇编代码生成,所有在平台见不一样.但理念是一样的,通过system call的数字标识,kernel在表中找到相应位置的处理函数.比如ARM定义的如下表格:// arch/arm/kernel/calls.S /* 0 */ CALL(sys_restart_syscall) CALL(sys_exit) CALL(sys_fork_wrapper) CALL(sys_read) CALL(sys_write) /* 5 */ CALL(sys_open) CALL(sys_close) CALL(sys_ni_syscall) /* was sys_waitpid */ CALL(sys_creat) CALL(sys_link) //...
- Return to User Mode
返回负值表示错误,正值和0说明成功.程序和kernel都不是对纯数字操作,而是使用符号定值,它们被定义在
include/asm-generic/errno-base.h和include/asm-generic/errno.h. 错误码直到并包括511被用来作为普通的错误, kernel特定的值使用512以上的.如下的错误码:
// <asm-generic/errno-base.h> #define EPERM 1 /* Operation not permitted */ #define ENOENT 2 /* No such file or directory */ #define ESRCH 3 /* No such process */ #define EINTR 4 /* Interrupted system call */ #define EIO 5 /* I/O error */ #define ENXIO 6 /* No such device or address */ #define E2BIG 7 /* Argument list too long */ #define ENOEXEC 8 /* Exec format error */ // ... // <asm-generic/errno.h> #define EDEADLK 35 /* Resource deadlock would occur */ #define ENAMETOOLONG 36 /* File name too long */ #define ENOLCK 37 /* No record locks available */ #define ENOSYS 38 /* Function not implemented */
在这里所有的码是正值,所以返回时在它们之前加负号.比如,返回
-ENOPERM来表示-1.Linux使用
long类型发送结果从kernle到用户空间.
Access to Userspace
尽管kernel代码已经尽最大努力分离kernel和用户空间,但还是有情况,kernel代码需要访问用户应用的虚拟内存.当如下两种情况:
- system call需要超过6个不同的参数,可以传入一个指向结构的指针.
- system call运行产生一大堆数据不能通过正常的返回机制返回给用户程序.这个数据需要交换到提前定义好的用户内存空间.
借助于特殊函数 copy_to_user 和 copy_from_user 来处理这个问题.
System Call Tracing
ptrace的system call是 sys_ptrace .架构独立部分在 kernel/ptrace.c.
架构相关部分的函数 arch_ptrace ,在 arch/arch/kernel/ptrace.c .基本代码流程如下:
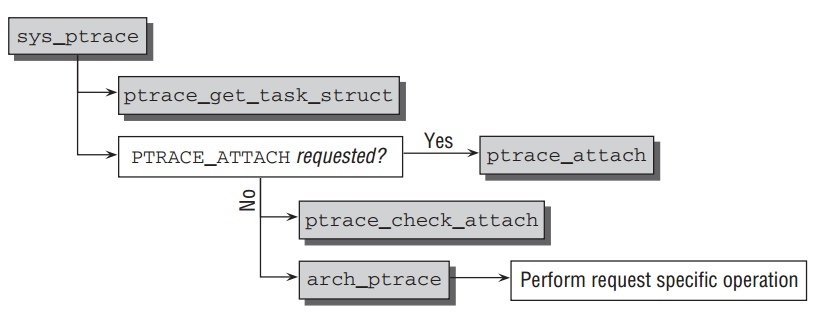
ptrace的system call由参数 request 所决定. 一开始必要的工作, 获取传入
PID的 task_struct 通过 ptrace_get_task_struct . 内部使用
find_task_by_vpid 来找出要求的 task_struct,并且防止追踪 init 进程.
- Starting Tracing
进程task结构中包含一些ptrace特定的元素:
<sched.h> struct task_struct { ... unsigned int ptrace; ... /* ptrace_list/ptrace_children forms the list of my children * that were stolen by a ptracer. */ struct list_head ptrace_children; struct list_head ptrace_list; ... struct task_struct *real_parent; /* real parent process (when being debugged) */ ... };
如果
PTRACE_ATTACH设置,ptrace_attach在追踪进程和目标进程建议一条链路.当它完成:- 目标进程的元素
ptrace设置到PT_TRACED. - 追踪进程成为目标进程的父进程.(真的父进程在
real_parent). - 被追踪进程被加入追踪的
ptrace_childrenlist中通过ptrace_list. - STOP信号被发送往被追踪进程.
如果不同于
PTRACE_ATTACH的行为被要求,ptrace_check_attach先检测追踪器是否附加到此进程上.然后由arch_ptrace进一步处理.进一步追踪行为由signal处理代码进行.当信号被传递,kernel检查进程
task_struct的ptrace是否被设置PT_TRACED标识,如果是, 进程的状态被设置为TASK_STOPPED来中断执行.notify_parent使用CHLD信号来通知追踪进程.然后追踪进程进行对目标进程需要的检查. - 目标进程的元素
Stopping Tracing
追踪关闭使用 PTRACE_DETACH ,使得ptrace把任务交给在 kernel/ptrace.c
中的 ptrace_detach , 主要完成如下步骤:
- 架构相关的
ptrace_disable做一些底层操作来停止追踪. TIF_SYSCALL_TRACE标识被从子进程中移除.- 进程
task_struct的元素ptrace被重置为0, 目标进程从最终进程的ptrace_childrenlist中移除. - 父进程重置通过设置
task_struct->parent为real_parent.
reference
ptrace_attach
int ptrace_attach(struct task_struct *task) { int retval; audit_ptrace(task); retval = -EPERM; if (unlikely(task->flags & PF_KTHREAD)) goto out; if (same_thread_group(task, current)) goto out; /* * Protect exec's credential calculations against our interference; * interference; SUID, SGID and LSM creds get determined differently * under ptrace. */ retval = -ERESTARTNOINTR; if (mutex_lock_interruptible(&task->cred_guard_mutex)) goto out; task_lock(task); retval = __ptrace_may_access(task, PTRACE_MODE_ATTACH); task_unlock(task); if (retval) goto unlock_creds; write_lock_irq(&tasklist_lock); retval = -EPERM; if (unlikely(task->exit_state)) goto unlock_tasklist; if (task->ptrace) goto unlock_tasklist; task->ptrace = PT_PTRACED; if (capable(CAP_SYS_PTRACE)) task->ptrace |= PT_PTRACE_CAP; __ptrace_link(task, current); send_sig_info(SIGSTOP, SEND_SIG_FORCED, task); retval = 0; unlock_tasklist: write_unlock_irq(&tasklist_lock); unlock_creds: mutex_unlock(&task->cred_guard_mutex); out: return retval; }
ptrace_detach
int ptrace_detach(struct task_struct *child, unsigned int data) { bool dead = false; if (!valid_signal(data)) return -EIO; /* Architecture-specific hardware disable .. */ ptrace_disable(child); clear_tsk_thread_flag(child, TIF_SYSCALL_TRACE); write_lock_irq(&tasklist_lock); /* * This child can be already killed. Make sure de_thread() or * our sub-thread doing do_wait() didn't do release_task() yet. */ if (child->ptrace) { child->exit_code = data; dead = __ptrace_detach(current, child); if (!child->exit_state) wake_up_process(child); } write_unlock_irq(&tasklist_lock); if (unlikely(dead)) release_task(child); return 0; }